
软件简介
八爪鱼采集器官方版是一款网页数据采集器,能够对各种不同类型的网页进行大量的数据采集工作,八爪鱼采集器官方版类型涵盖广泛,金融类、交易类、社交网站、电商商品等的网站数据都能够被规范性的采集下来,并且可以被导出,软件界面十分简洁明晰,并且软件使用起来方便快捷,是一款非常实用,且又功能性强大的软件,让繁琐复杂的工作变得简单有趣!
功能介绍
简单来讲,使用八爪鱼可以非常容易的从任何网页精确采集你需要的数据,生成自定义的、规整的数据格式。八爪鱼数据采集系统能做的包括但并不局限于以下内容:
1. 金融数据,如季报,年报,财务报告, 包括每日最新净值自动采集;
2. 各大新闻门户网站实时监控,自动更新及上传最新发布的新闻;
3. 监控竞争对手最新信息,包括商品价格及库存;
4. 监控各大社交网站,博客,自动抓取企业产品的相关评论;
5. 收集最新最全的职场招聘信息;
6. 监控各大地产相关网站,采集新房二手房最新行情;
7. 采集各大汽车网站具体的新车二手车信息;
8. 发现和收集潜在客户信息;
9. 采集行业网站的产品目录及产品信息;
10. 在各大电商平台之间同步商品信息,做到在一个平台发布,其他平台自动更新。
八爪鱼采集器软件特色
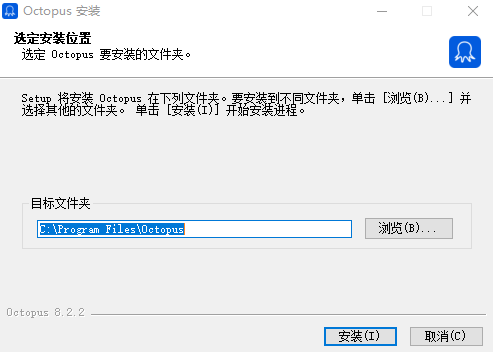
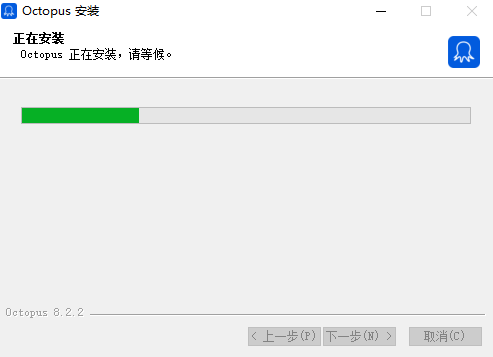
八爪鱼采集器安装步骤
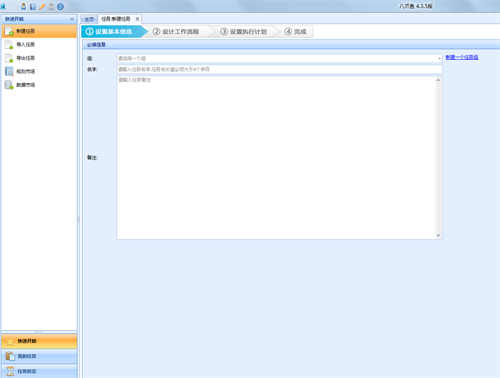
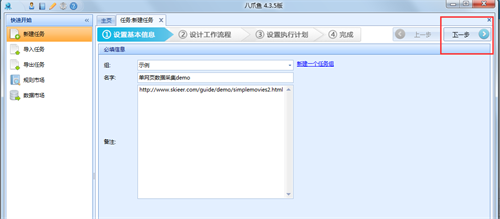
八爪鱼采集器官方电脑端更新日志
八爪鱼采集器官方电脑端常见问题
- 按键精灵手机助手 官方版
- AutoPix
- 无忧网络锁
- Windows 7 & Vista Firewall Control
- Spyware Terminator Database Update
- Max PC Privacy (64-bit)
- Avast Browser Cleanup
- E盾护航防沉迷系统
- 恶意网站HOSTS屏蔽文件自动升级程序1.6
- Malware Sniper
- CryptoX
- Secure Lockdown - Multi Application Edition
- Portable PrivaZer
- ImageBox 网页图片批量下载(64Bit)
- 迅捷fast无线路由器快速安装工具
- Internet Image Collector
- Feature Creature
- Moin11(Win11兼容检测工具)
- Net Vampire
- 搜苹果PC客户端
- 迷你快车(FlashGet Mini)
- Tp-Link管理工具
- TLWR740n固件V3V4
- 杭星路由器管理软件
- ncstudio(雕刻机控制系统)
- 睡眠白噪音
- K5噪音分贝仪
- 溧水114
- 渝快办
- 亲邻开门
- 首都航空
- 市民网
- 北京数字文化馆
- 沛县便民网
- 骑砍中文站
- 众妖之怒 1.10.1
- 巨龙之战 0.2.70
- 王牌装甲师 1.0.9
- 战车联盟 1.0.0
- 霸战三国 1.0.0
- 全民大拉轰 1.0.0
- Impossible shots 1.15
- dragonet 3.11
- 色彩韵律 2.0.0
- 智力破解拆除 1.2
- 吐刚茹柔
- 吐根
- 吐故纳新
- 吐话,吐话儿
- 吐口
- 吐露
- 吐沫
- 吐气
- 吐气扬眉
- 吐弃
- [BT下载][天地拳王][WEB-MKV/2.11GB][国粤语配音/中文字幕][4K-2160P][H265编码][流媒体][SONYHD小组作品]
- [BT下载][无间杀手/死人的复][BD-MKV/7G][英语中字][1080p][经典刺激]
- [BT下载][疯狂的麦克斯:狂暴女神][BD-MKV/8.61GB][国英多音轨/简繁英字幕][1080P][H265编码][蓝光压制][SONYHD小组作品]
- [BT下载][幽灵鬼屋][BD-MKV/21.48GB][简繁英字幕][4K-2160P][HDR版本][H265编码][蓝光压制][SONYHD小组作品]
- [BT下载][马鲁姆][BD-MKV/4.40GB][简繁英字幕][1080P][蓝光压制][SONYHD小组作品]
- [BT下载][马鲁姆][BD-MKV/2.91GB][简繁英字幕][1080P][H265编码][蓝光压制][SONYHD小组作品]
- [BT下载][交战规则][BD-MKV/12.50GB][简繁英字幕][1080P][蓝光压制][SONYHD小组作品]
- [BT下载][蜘蛛侠:英雄无归][BD-MKV/19.72GB][简繁英字幕][4K-2160P][HDR+杜比视界双版本][H265编码][蓝光压制][SONYHD小组作品
- [BT下载][致命约会][BD-MKV/9.45GB][简体字幕][1080P][蓝光压制][CTRLHD小组作品]
- [BT下载][致命约会][BD-MKV/6.12GB][简体字幕][1080P][H265编码][蓝光压制][CTRLHD小组作品]
- [BT下载][南波万的聚会.第三季][第01-03集][WEB-MP4/14.09G][国语配音/中文字幕][4K-2160P][H265][流媒体][
- [BT下载][卿本佳人][短剧][第15-16集][WEB-MKV/0.60G][国语配音/中文字幕][4K-2160P][H265][流媒体][ParkTV]
- [BT下载][双花镜][全20集][WEB-MKV/1.83G][国语配音/中文字幕][1080P][H265][流媒体][ZeroTV]
- [BT下载][双花镜][短剧][全20集][WEB-MKV/3.82G][国语配音/中文字幕][4K-2160P][H265][流媒体][ParkTV]
- [BT下载][双花镜][全20集][WEB-MKV/4.27G][国语配音/中文字幕][4K-2160P][H265][流媒体][ZeroTV]
- [BT下载][嗨1995][短剧][第29-32集][WEB-MKV/1.42G][国语配音/中文字幕][4K-2160P][H265][流媒体][ParkTV]
- [BT下载][国土安全.第五季][全12集][WEB-MKV/38.41G][简繁英字幕][1080P][Disney+][流媒体][ParkTV]
- [BT下载][国土安全.第六季][第01-02集][WEB-MKV/6.47G][简繁英字幕][1080P][Disney+][流媒体][ParkTV]
- [BT下载][大梦归离][第01-02集][WEB-MKV/5.49G][国语配音/中文字幕][4K-2160P][HDR+杜比视界双版本][H265][
- [BT下载][女子推理社.第二季][第05-06集][WEB-MP4/8.28G][国语配音/中文字幕][4K-2160P][H265][流媒体][Lel
- 【幻灵解析】菲萝-太阳血脉的后裔
- 【幻灵解析】诺亚-诺亚大陆T0级真神
- 诺亚之心第六天——混沌秘境
- 【幻灵解析】雅芙-迅捷!极限输出
- 【幻灵解析】雪琳-侦探少女
- 诺亚之心第五天——星座教程
- 诺亚之心第四天——奇遇探索
- 诺亚之心第三天——装备提升
- 诺亚之心第二天——玩法教程
- 诺亚之心第一天——升级教程
- 搜狗输入法Mac版
- 石墨文档Mac版
- 开搜AI64位MAC版
- 迅捷AIPPT MAC版
- 华为云会议MAC版
- 小鱼AI写作MAC版
- 全能翻译官Mac版
- 有道词典Mac版
- 极光PDFMac版
- 弹幕单词Mac版